Reduce SD Card Wear AND Get More RAM on your Raspberry Pi
How you can reduce SD card wear from system logging and increase perceived memory capacity at the same time on your Raspberry Pi with zram-config

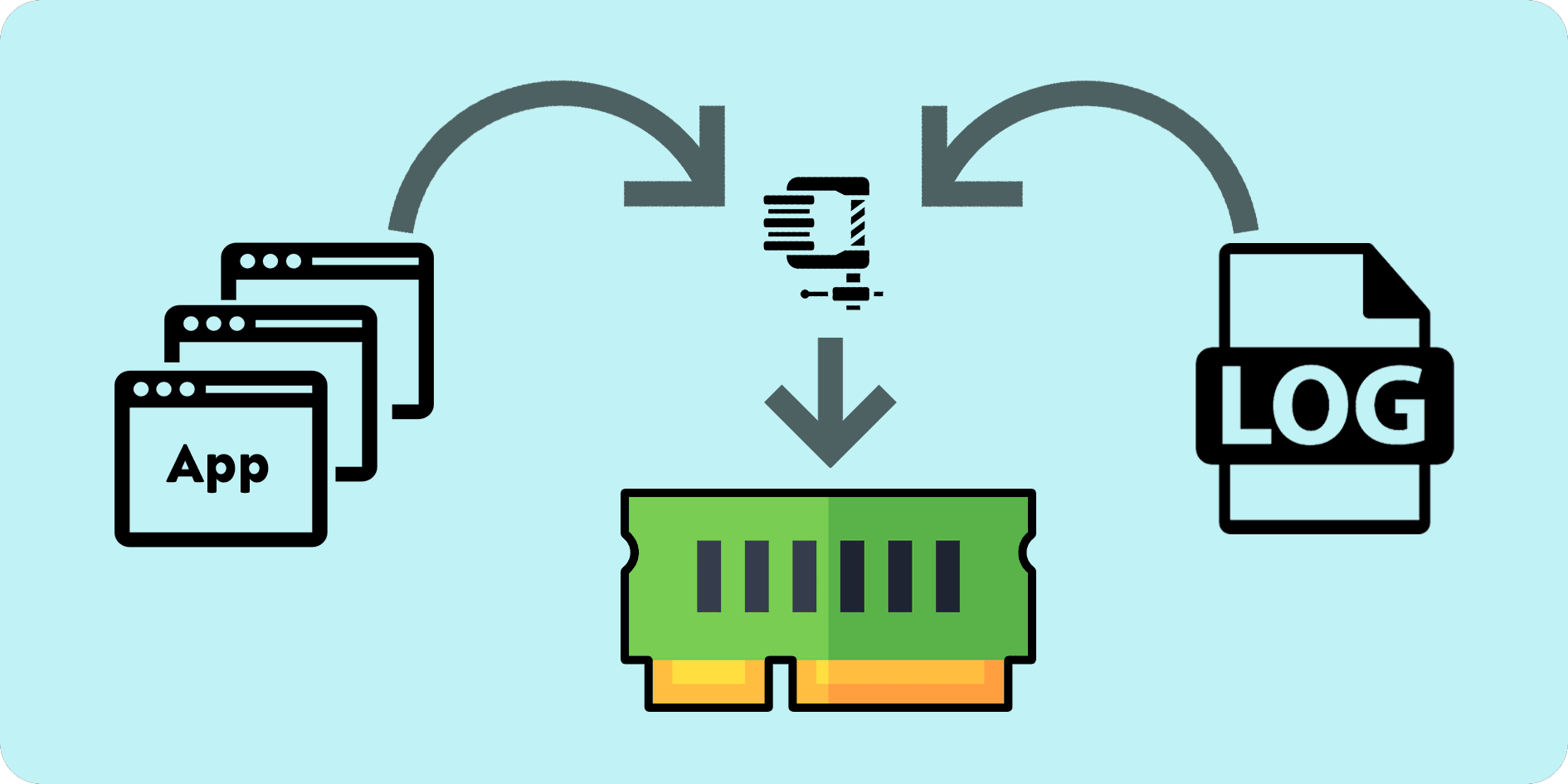
It's been almost 3 years since I wrote about extending the lifespan of your SD card on, and squeezing more RAM out of, your Raspberry Pi using log2ram and zram-swap-config respectively. Since then, COVID has come and gone, open-source projects too have come and gone. Tools that I recommended in the past may no longer be actively maintained or necessarily the best tool for the job.
Back then, there was one tool for each purpose, one for creating swap out of compressed memory and one for logging to ram/zram. Between then and now, the creator of zram-swap-config started (and handed over stewardship of) another project known as zram-config which combines both of those tools, allowing users to configure zram logging and swap with a single unified tool.
Disclaimer: No offence to the authors of abandoned projects out there. Life exacts a varying toll on the schedules of everyone, starting a project is easy, but maintaining one is really, really hard. I know because I myself am guilty of leaving my projects for long periods of time.
Kudos to all creators and maintainers out there for keeping their work alive!
Fortunately, even if open-source projects go unmaintained, precisely because it's open-source, people are always free to fork them and take over stewardship of the project. This is exactly what happened to StuartIanNaylor/zram-config where the project has been mostly handed over to ecdye over at ecdye/zram-config who continues to make improvements, big and small, to the codebase.
This is exactly the tool that I will be recommending today.
 ecdye
ecdyeWhat it does?
In case you might have missed my 2 previous blog posts, this tool has 2 main functions:
- Create a compressed swap partition from a portion of your RAM
- Create a compressed block partition from a portion of your RAM to store logs
I will take some time to rehash some of the knowledge shared in the previous blog posts in the following section. If you're already familar, skip to the next section on how you can set up zram-config.
Compressed swap partition
This serves to increase the perceived memory capacity from the perspective of system processes, achieved by setting aside a portion of RAM and then applying on-the-fly compression on incoming data being written as well as decompression of outgoing data being read.
Example
128MiBof memory is set aside for zram swap- zram is configured to use
lzo-rle, a relatively fast compression algorithm that achieves on average2.1xcompression ratio - An application would see
128 * 2.1 = 268.8MiBof free memory instead of the original128MiBof physical memory
For zram swap to be feasible with minimal performance impact, several conditions must be satisfied:
- The machine's processor must be sufficiently modern where it is able to handle compression efficiently (all Raspberry Pis are considered modern enough).
- The chosen compression algorithm must have sufficiently high throughput, generally on the order of several GiB/s read and around 800MiB/s write (reads are usually more important than writes in memory)
My personal take
This feature is especially important for memory-constrained devices such as a Raspberry Pi and is probably most applicable for variants with the least amount of memory (Zero 2w, Zero W, 3B+, etc.).
Even if you own a 8GiB version of the Raspberry Pi 4, having a compressed swap partition wouldn't hurt as well. It might even be beneficial by preventing catastrophic system OOM events when running applications that have a rather unpredictable memory consumption pattern.
Compressed log partition
This creates a filesystem partition out of a portion of RAM applying on-the-fly compression on incoming data being written as well as decompression of outgoing data being read.
Example
128MiBof memory is set aside for zram logging- zram is configured to use
zstdas the compression algorithm, a relatively slow compression algorithm that achieves on average2.9xcompression ratio - zram mounts that portition of memory on the system logging directory (typically
/var/log) - Logs being written to /var/log no longer write directly to disk and are compressed on-the-fly before being stored in the zram paritition in memory
Intricacies
- Existing log files present in
/var/logare moved to thebind_dirdirectory (defaults to/opt/zram/log.bind - When the zram service is stopped, the log files are synced the bind directory, then all zram partitions are unmounted
- When log rotation occurs, compressed logs are written to disk at the configured
oldlog_dirdirectory (defaults to/opt/zram/oldlog)
My personal take
This is perhaps my absolute favourite feature of using zram overall. It plays 2 very important roles, especially for Raspberry Pi and similar devices.
Firstly, it protects your SD card from wear from the constant small writes from writing logs from the OS and applications. For context, the lifespan of an SD card (and any form of flash memory, even SSDs for that matter) is strongly influenced by how many write operations each cell experiences over its lifetime.
A cell can be thought of as the smallest unit of storage in the data medium, storing a single or several units of binary data (1 or 0), depending on the NAND chip's architecture. This is the foundation of NAND flash storage that underlies SD cards, flash drives, and even SSDs. At the risk of oversimplifying, SD cards can be intuited as low-quality, budget NAND storage, and NVMe drives as high-quality NAND storage, both use the same technology, but NVMe drives last longer due to better quality and wear-levelling mechanisms.
With zram logging, logs never actually get written to disk, only on rotation or termination of the zram service do they get fully persisted to disk. As a result, this extends your SD card's lifespan significantly.
Secondly, it allows you to store stupid amounts of logs in memory, significantly more than what you can achieve on disk with an identical amount of space. This is because compression algorithms like zstd and lzo work best on text data, which coincidentally, is precisely all that logs are; text.
Compression ratio estimates out there are calculated based on the expected data types that the compression task would handle, and that typically assumes some percentage of incompressible data such as videos and images that cannot be compressed without loss of fidelity. Using compression on a partition that is dedicated for storing logs means that we can stretch compression ratio estimates to an absurd number. For example, for zstd, the average compression ratio is 2.9x, but for logs we can probably safely assume it achieves up to 5x compression. (With 128MiB of RAM, using zram, we can get up to 640MiB of space for logs!)
As such, even if you don't use zram swap, zram logging is an absolute must-have if you have a Single Board Computer running on flash storage such as SD cards.
How to set it up
You may choose to follow the instructions on the README for zram-config.
However, if you're lazy to figure out that out, I have an ansible role for you.
ikaruswillBasic requirements
Clone my repository
git clone https://github.com/ikaruswill/ansible-roles.git && \
cd ansible-roles[Optional] Create a python virtual environment
python -m venv env && \
source env/bin/activateInstall requirements
pip install -r requirements.txtConfiguring the ansible inventory
Customize the inventory.yml to include your target hosts, I assume that you already have SSH keys set up. You may configure more than 1 host if you have multiple machines.
The example inventory assumes that you have only 1 machine, with a hostname of raspberrypi and a username of pi. You may change those variables to values that suit your setup.
Additionally, the following variables may be set for certain scenarios:
ansible_ssh_private_key_file: Path to your private key, by default it attempts all private keys of the path:~/.ssh/id_<alg>ansible_ssh_pass: If you are still using password authentication (please don't), you may set this variable to your password to tell ansible to login with password authentication
---
all:
hosts:
raspberrypi:
ansible_user: piConfiguring the playbook
Configure the zram parameters for each device. Check the README file in the role for more information on the parameters. I have included parameters for a minimal setup in the example playbook below.
---
- hosts: all
roles:
- zram
vars:
zram_log:
alg: lzo-rle
mem_limit: 64M
disk_size: 192M
zram_swap:
alg: lzo-rle
mem_limit: 512M
disk_size: 1024M
Save the playbook as something like zram.yml and run the playbook!
ansible-playbook zram.ymlProfit!
Recommendations
Based on my experience with a Raspberry Pi 4, I have some recommendations on the settings that you can adopt.
Compression algorithm availability
Before choosing a compression algorithm from the list, do note that you are limited mainly on what compression algorithms are available in your OS. You can find that with the following command:
modprobe zram && cat /sys/block/zram0/comp_algorithmThe output will be something akin to the following:
lzo [lz4] deflateThis shows the available compression algorithms as well as the currently selected compression algorithm enclosed by the square braces.
Compression algorithm choice
This chart from facebook/zstd provides a good benchmark for the performance of the different compressors.
| Compressor name | Ratio | Compression | Decompression |
|---|---|---|---|
| zstd 1.5.1 -1 | 2.887 | 530 MB/s | 1700 MB/s |
| zlib 1.2.11 -1 | 2.743 | 95 MB/s | 400 MB/s |
| brotli 1.0.9 -0 | 2.702 | 395 MB/s | 450 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 540 MB/s | 760 MB/s |
| lzo1x 2.10 -1 | 2.106 | 660 MB/s | 845 MB/s |
| lz4 1.9.3 | 2.101 | 740 MB/s | 4500 MB/s |
| lzf 3.6 -1 | 2.077 | 410 MB/s | 830 MB/s |
| snappy 1.1.9 | 2.073 | 550 MB/s | 1750 MB/s |
disk_size
Set this value in each use casemem_limit * compression ratio
Log mem_limit
As mentioned prior, log partitions consists of primarily (if not purely) text data, so it is safe to bump the compression ratios higher, generally by around double.
Given the higher achievable compression ratio, we can set mem_limit to a low value such as 64M. I find that as long as you achieve a disk_size of around 200M, your setup is safe even for the most verbose applications.
Swap mem_limit
Generally RAM contains a mixture of text and other data so it's best to stick to the estimated compression ratios.
For swap, mem_limit depends on the available memory on your machine. For machines with more CPU cores (Raspberry Pi 4) it is safe to dedicate 50% of your RAM to zram swap, i.e. 2048M for a 4GB Raspberry Pi 4, 4096M for a 8GB Raspberry Pi 4.
Closing
It's good to get back to writing blogs after a long tumultous period of FUD. Shout out to my mentor Fabrice as well as my partners in the crime of self-hosting, Elroy and Joseph for the much needed motivation to write again. Thanks for the support folks.
Do look forward to many more exciting pieces based on the discoveries I've made over the past few years of Kubernetes at work and at home when self-hosting!