The Flaw in BGP Load-balancing in MetalLB
I was blindsided by the unavoidable violation of separation of concerns.

I was just firing commits at my self-hosted Gitea server just as I would every evening but this time, something changed. I was unable to connect to Gitea via its public SSH endpoint.
The service must be down again, just another day in a self-hoster's life, I thought.
But it turns out, the web UI is alive and kicking, in fact, it's so alive that it's responding faster than it usually does.
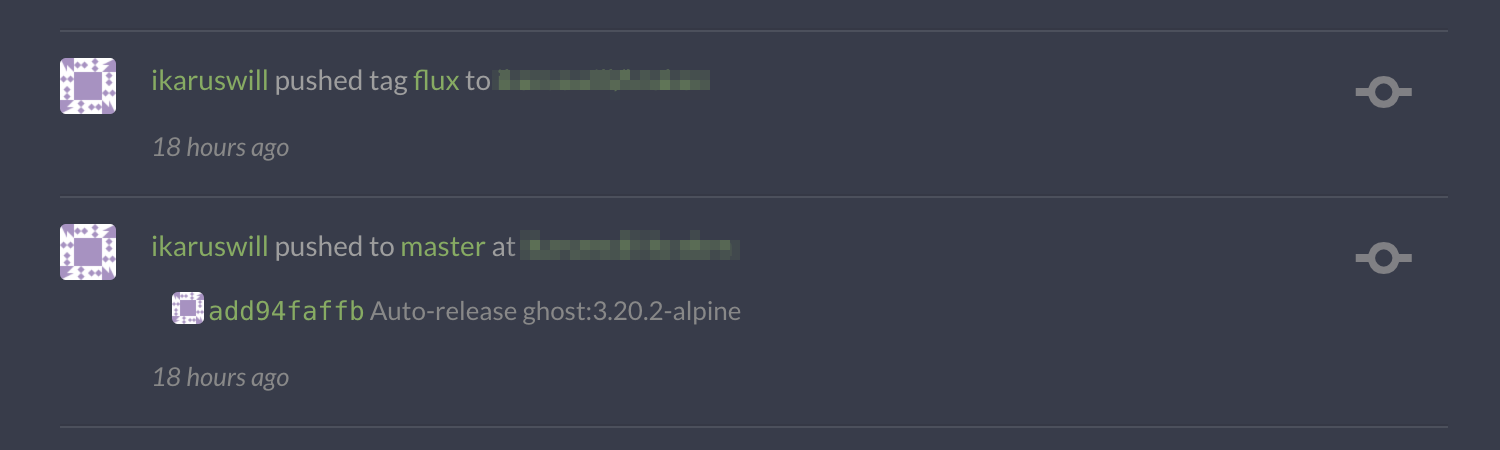
What's even more interesting is that Flux, my Kubernetes continuous deployment service has recently pushed container image updates 18 hours ago but it seems like my MacBook's Git client's auto-pulls stopped since 26 hours ago. Something was obviously amiss there. Something with SSH connections from the internet and not within the cluster.
Testing connections locally
Command-line diagnostics confirm my hypothesis of issues present with connections from external sources.
$ ssh -t [email protected]
ssh: connect to host myhiddengiteahost.com port 22: Operation timed out
$ ping leviathan3
PING leviathan3 (192.168.3.33): 56 data bytes
64 bytes from 192.168.3.33: icmp_seq=0 ttl=64 time=6.107 ms
64 bytes from 192.168.3.33: icmp_seq=1 ttl=64 time=4.827 ms
--- leviathan3 ping statistics ---
2 packets transmitted, 2 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 4.827/5.467/6.107/0.640 ms$ kubectl port-forward service/gitea 2200:22
Forwarding from 127.0.0.1:2200 -> 22
Forwarding from [::1]:2200 -> 22
$ ssh -t git@localhost -p 2200
The authenticity of host '[localhost]:2200 ([127.0.0.1]:2200)' can't be established.
ECDSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '[localhost]:2200' (ECDSA) to the list of known hosts.
PTY allocation request failed on channel 0The next logical step was then to check the connection between the router and the cluster.
The next suspect
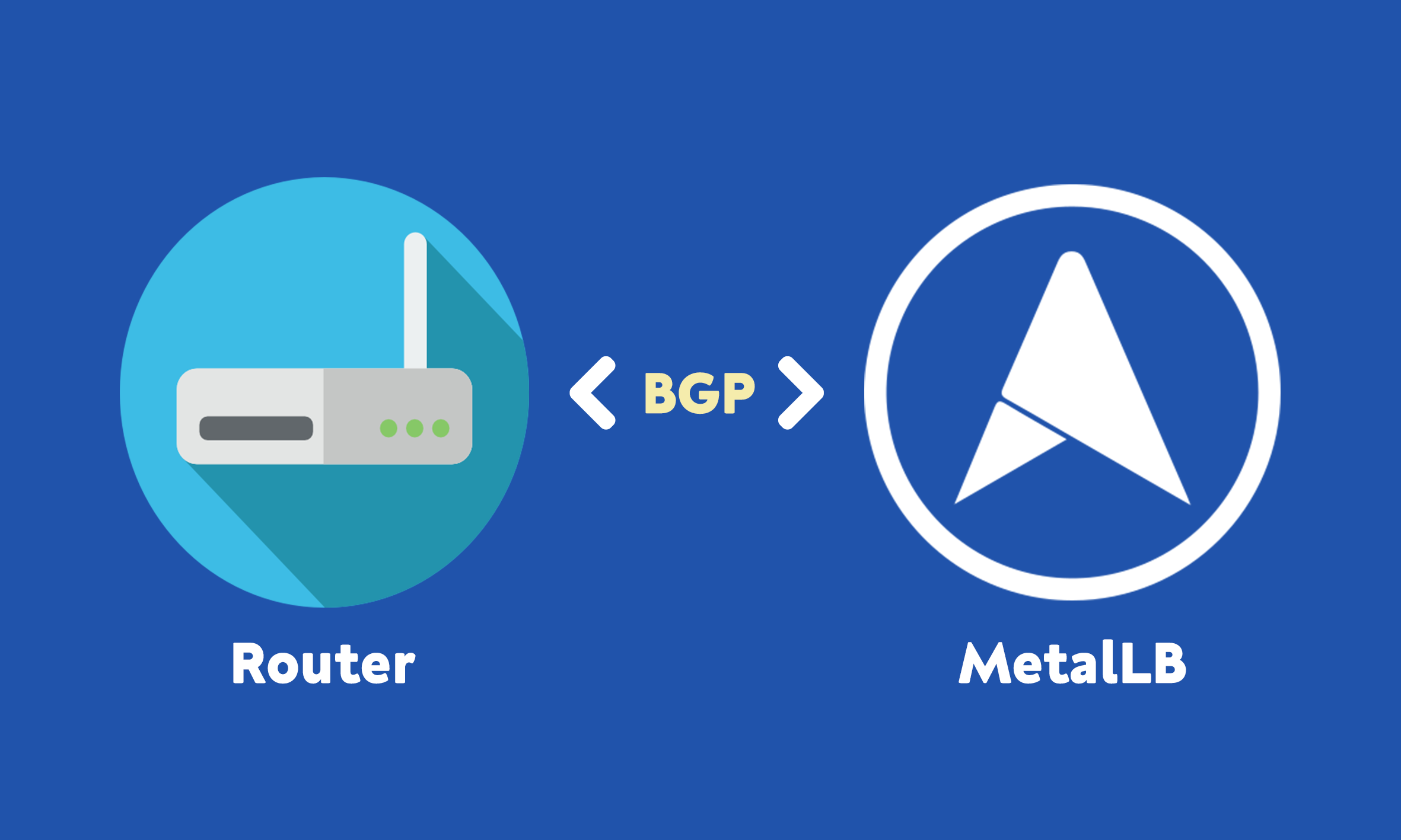
I use MetalLB, a load-balancer implementation using standard routing protocols, for bare-metal Kubernetes clusters. Specifically, I use MetalLB in BGP (Border Gateway Protocol) mode, which is the recommended mode for reduced network hops and symmetrical traffic distribution between service pods.
Border Gateway Protocol (BGP) is a standardized exterior gateway protocol designed to exchange routing and reachability information among autonomous systems (AS) on the Internet. (Wikipedia)
In BGP mode, MetalLB establishes a BGP peering session with your network routers to advertise the IPs of cluster services, so that the routers will load-balance between them.
Zooming in to the load-balancing that is performed by the router via BGP
$ configure
$ show ip bgp route
IP Route Table for VRF "default"
B *> 192.168.30.1/32 [200/0] via 192.168.3.32, switch0, 00:02:28
*> [200/0] via 192.168.3.31, switch0, 00:02:28
B *> 192.168.30.20/32 [200/0] via 192.168.3.31, switch0, 00:03:05
B *> 192.168.30.21/32 [200/0] via 192.168.3.31, switch0, 00:03:05
B *> 192.168.30.53/32 [200/0] via 192.168.3.16, switch0, 00:02:38
*> [200/0] via 192.168.3.13, switch0, 00:02:38
B *> 192.168.30.254/32 [200/0] via 192.168.3.32, switch0, 00:02:10
*> [200/0] via 192.168.3.15, switch0, 00:02:10There were 2 obvious problems here.
- In my cluster, Traefik, my reverse proxy, has a LoadBalancerIP of
192.168.30.1and has 3 replicas, one on each node on the Leviathan cluster. In the output above, there were only 2 next hop (via) addresses corresponding to leviathan1 and leviathan2. But where is leviathan3 @192.168.3.33? - I designated
192.168.3.22as the LoadBalancerIP for my Gitea SSH service, but that too, is nowhere to be found on the BGP routes list.
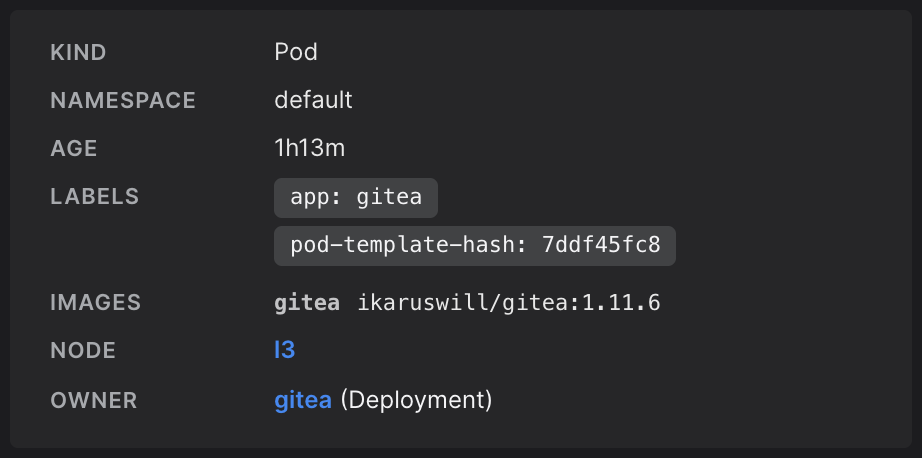
Checking Infra.app reveals a striking coincidence. Gitea is also located on leviathan3, the same node that seems to be missing from Traefik's BGP routes list.
When it comes to infrastructure, there are no such things as coincidences, especially when it comes to problems.
The blunder with BGP load-balancing
A quick check on the EdgeRouter CLI confirms my suspicion.
$ show protocols bgp
bgp 64512 {
maximum-paths {
ibgp 32
}
neighbor 192.168.3.11 {
remote-as 64512
}
neighbor 192.168.3.12 {
remote-as 64512
}
neighbor 192.168.3.13 {
remote-as 64512
}
neighbor 192.168.3.14 {
remote-as 64512
}
neighbor 192.168.3.15 {
remote-as 64512
}
neighbor 192.168.3.16 {
remote-as 64512
}
neighbor 192.168.3.17 {
remote-as 64512
}
neighbor 192.168.3.31 {
remote-as 64512
}
neighbor 192.168.3.32 {
remote-as 64512
}
parameters {
router-id 192.168.3.1
}
}Referring back to a guide I followed to set up BGP load-balancing on the EdgeRouter X, I searched for possible debugging steps I could follow. It was then I realized I had made a huge blunder.
I had missed out one critical configuration step 2 months ago, when adding leviathan3 to the cluster.
I did not add leviathan3 as a BGP neighbor on the router.
$ set protocols bgp 64512 neighbor 192.168.3.33 remote-as 64512$ kubectl get nodes l3
NAME STATUS ROLES AGE VERSION
l3 Ready worker 59d v1.17.6+k3s1All these mean that leviathan3 was running a whole 59 days but no external traffic could reach it. It was basically not accepting any web traffic and certainly not offloading the other 2 Traefik instances. Should there be a case where leviathan3 somehow became the last node alive in the Leviathan cluster, where my Traefik instances are distributed, this would mean an outage on all my web services, including this blog.
The thought of how it slipped through the cracks and I failed to spot that for a whole 59 days terrifies me.
How did this happen?
I will not make excuses and discount the fact that this is due to my own negligence, but this is due in no small part to a configuration storage design issue when using MetalLB's BGP mode in a bare-metal Kubernetes cluster.
The router managing the configuration of the Kubernetes cluster connectivity is an exemplification of a violation of separation of concerns.
In computer science, separation of concerns (SoC) is a design principle for separating a computer program into distinct sections such that each section addresses a separate concern. A concern is a set of information that affects the code of a computer program. (Wikipedia)
The router should only be concerned with the reachability of devices (Layer 4) in the subnet it manages, something that BGP is designed to do. However, in the case of MetalLB's BGP mode, it uses BGP as an application-aware protocol, requiring the router to have knowledge of all nodes Kubernetes runs on (Layer 7).
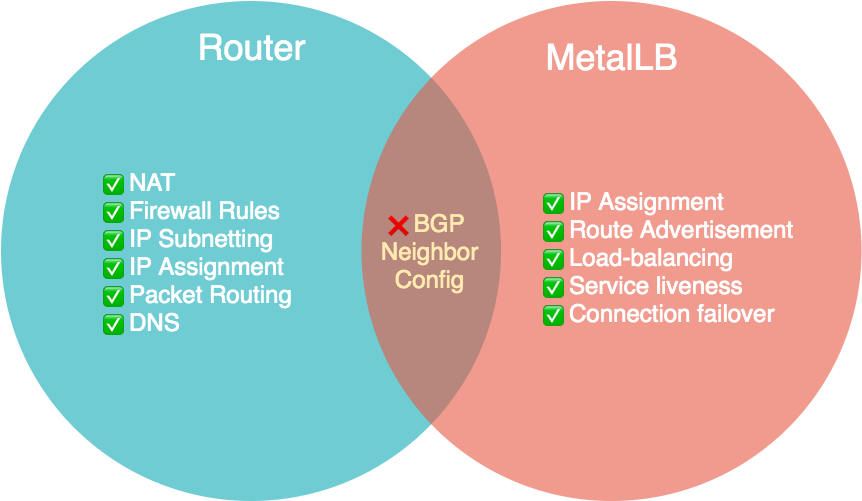
Therefore, when provisioning a new machine intended for Kubernetes, one does not just have to configure a static IP and static DNS for the machine on the router, but also set the new machine as a BGP neighbor on the router before even installing Kubernetes.
What now?
Unfortunately, there's pretty much nothing we can do right now with the current (sad) state of Kubernetes Load Balancers on bare-metal setups.
With great power comes great responsibility.
Such is the price that comes with the power and excitement of being on the cutting edge of application deployment; everything is constantly under development.
Some may highlight the presence of Layer 2 mode in MetalLB as an alternative, but I personally beg to differ as I would not even call that load balancing but more of failover. That's because in Layer 2 mode, traffic is not evenly distributed across all application instances, but rather only to the leader-elected node until it is no longer the leader due to outage or some other reason.
... in layer2 mode a single leader-elected node receives all traffic for a service IP. This means that your service’s ingress bandwidth is limited to the bandwidth of a single node. (MetalLB)
In MetalLB's defence, they are doing a great job with democratizing Kubernetes load-balancers by enabling on-premise setups without the need for cloud load-balancers which Kubernetes has strong native support for. What is unfortunate is that there is no native support nor is there currently a clean solution on the horizon for on-premise Kubernetes service load-balancing.
What we can do now is perhaps only to raise the awareness of the community on this missing piece of the puzzle, and to report issues and contribute to MetalLB's development. Hopefully through the combined intelligence of the community, we may arrive at a solution soon.